

Maybe AI Isn’t Going To Replace You At Work After All
Authored by Charles Hugh Smith via OfTwoMinds blog,
AI fails at tasks where accuracy must be absolute to create value.
In reviewing the on-going discussions about how many people will be replaced by AI, I find a severe lack of real-world examples. I’m remedying this deficiency with an example of AI’s failure in the kind of high-value work that many anticipate will soon be performed by AI.
Few things in life are more pervasively screechy than hype, which brings us to the current feeding-frenzy of AI hype. Since we all read the same breathless claims and have seen the videos of robots dancing, I’ll cut to the chase: Nobody posts videos of their robot falling off a ladder and crushing the roses because, well, the optics aren’t very warm and fuzzy.
For the same reason, nobody’s sharing the AI tool’s error that forfeited the lawsuit. The only way to really grasp the limits of these tools is to deploy them in the kinds of high-level, high-value work that they’re supposed to be able to do with ease, speed and accuracy, because nobody’s paying real money to watch robots dance or read a copycat AI-generated essay on Yeats that’s tossed moments after being submitted to the professor.
In the real world of value creation, optics don’t count, accuracy counts. Nobody cares if the AI chatbot that churned out the Yeats homework hallucinated mid-stream because nobody’s paying for AI output that has zero scarcity value: an AI-generated class paper, song or video joins 10 million similar copycat papers / songs / videos that nobody pays attention to because they can create their own in 30 seconds.
So let’s examine an actual example of AI being deployed to do the sort of high-level, high-value work that it’s going to need to nail perfectly to replace us all at work. My friend Ian Lind, whom I’ve known for 50 years, is an investigative reporter with an enviably lengthy record of the kind of journalism few have the experience or resources to do. (His blog is www.iLind.net, ian@ilind.net)
The judge’s letter recommending Ian for the award he received from the American Judges Association for distinguished reporting about the Judiciary ran for 18 pages, and that was just a summary of his work.
Ian’s reporting/blogging in the early 2000s inspired me to try my hand at it in 2005.
Ian has spent the last few years helping the public understand the most complex federal prosecution case in Hawaii’s recent history, and so the number of documents that have piled up is enormous. He’s been experimenting with AI tools (NotebookLM, Gemini, ChatGPT) for months on various projects, and he recently shared this account with me:
„My experience has definitely been mixed. On the one hand, sort of high level requests like 'identify the major issues raised in the documents and sort by importance’ produced interesting and suggestive results. But attempts to find and pull together details on a person or topic almost always had noticeable errors or hallucinations. I would never be able to trust responses to even what I consider straightforward instructions. Too many errors. Looking for mentions of 'drew’ in 150 warrants said he wasn’t mentioned. But he was, I’ve gone back and found those mentions. I think the bots read enough to give an answer and don’t keep incorporating data to the end. The shoot from the hip and, in my experience, have often produced mistakes. Sometimes it’s 25 answers and one glaring mistake, sometimes more basic.”
Let’s start with the context. This is similar to the kind of work performed by legal services. Ours is a rule-of-law advocacy system, so legal proceedings are consequential. They aren’t a ditty or a class paper, and Ian’s experience is mirrored by many other professionals.
Let’s summarize AI’s fundamental weaknesses:
1. AI doesn’t actually „read” the entire collection of texts. In human terms, it gets „bored” and stops once it has enough to generate a credible response.
2. AI has digital dementia. It doesn’t necessarily remember what you asked for in the past nor does it necessarily remember its previous responses to the same queries.
3. AI is fundamentally, irrevocably untrustworthy. It makes errors that it doesn’t detect (because it didn’t actually „read” the entire trove of text) and it generates responses that are „good enough,” meaning they’re not 100% accurate, but they have the superficial appearance of being comprehensive and therefore acceptable. This is the „shoot from the hip” response Ian described.
In other words, 90% is good enough, as who cares about the other 10% in a college paper, copycat song or cutesy video.
But in real work, the 10% of errors and hallucinations actually matter, because the entire value creation of the work depends on that 10% being right, not half-assed.
In the realm of LLM AI, getting Yeats’ date of birth wrong–an error without consequence–is the same as missing the defendant’s name in 150 warrants. These programs are text / content prediction engines; they don’t actually „know” or „understand” anything. They can’t tell the difference between a consequential error and a „who cares” error.
This goes back to the classic AI thought experiment The Chinese Room, which posits a person who doesn’t know the Chinese language in a sealed room shuffling symbols around that translate English words to Chinese characters.
From the outside, it appears that the black box (the sealed room) „knows Chinese” because it’s translating English to Chinese. But the person–or AI agent–doesn’t actually „know Chinese”, or understand any of what’s been translated. It has no awareness of languages, meanings or knowledge.
This describes AI agents in a nutshell.
4. AI agents will claim their response is accurate when it is obviously lacking, they will lie to cover their failure, and then lie about lying. If pressed, they will apologize and then lie again. Read this account to the end: Diabolus Ex Machina.
In summary: AI fails at tasks where accuracy must be absolute to create value. lacking this, it’s not just worthless, it’s counter-productive and even harmful, creating liabilities far more consequential than the initial errors.
„But they’re getting better.” No, they’re not–not in what matters. AI agents are probabilistic text / content prediction machines; they’re trained parrots in the Chinese Room. They don’t actually „know” anything or „understand” anything, and adding another gazillion pages to their „training” won’t change this.
The Responsible Lie: How AI Sells Conviction Without Truth:
„The widespread excitement around generative AI, particularly large language models (LLMs) like ChatGPT, Gemini, Grok, and DeepSeek, is built on a fundamental misunderstanding. While these systems impress users with articulate responses and seemingly reasoned arguments, the truth is that what appears to be 'reasoning’ is nothing more than a sophisticated form of mimicry.
These models aren’t searching for truth through facts and logical arguments–they’re predicting text based on patterns in the vast datasets they’re 'trained’ on. That’s not intelligence–and it isn’t reasoning. And if their 'training’ data is itself biased, then we’ve got real problems.
I’m sure it will surprise eager AI users to learn that the architecture at the core of LLMs is fuzzy–and incompatible with structured logic or causality. The thinking isn’t real, it’s simulated, and is not even sequential. What people mistake for understanding is actually statistical association.”
AI Has a Critical Flaw — And it’s Unfixable
„AI isn’t intelligent in the way we think it is. It’s a probability machine. It doesn’t think. It predicts. It doesn’t reason. It associates patterns. It doesn’t create. It remixes. Large Language Models (LLMs) don’t understand meaning — they predict the next word in a sentence based on training data.”
Let’s return now to the larger context of AI replacing human workers en masse. This post by Michael Spencer of AI Supremacy and Jing Hu of 2nd Order Thinkers offers a highly informed and highly skeptical critique of the hype that AI will unleash a tsunami of layoffs that will soon reach the tens of millions. Will AI Agents really Automate Jobs at Scale?
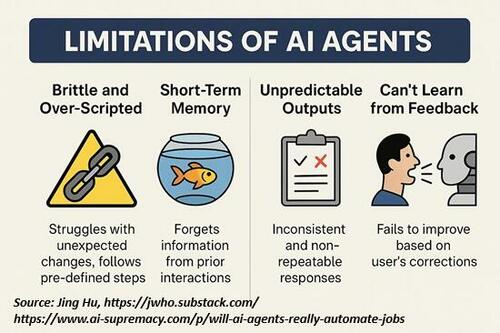
Jing Hu explains the fundamental weaknesses in all these agents: it’s well worth reading her explanations and real-world examples in the link above. Here is an excerpt:
„Today’s agents have minimal true agency.
Their 'initiative’ is largely an illusion; behind the scenes, they follow (or are trying to) tightly choreographed steps that a developer or prompt writer set up.
If you ask an agent to do Task X, it will do X, then stop. Ask for Y, and it does Y. But if halfway through X something unexpected happens, say a form has a new field, or an API call returns an error, the agent breaks down.
Because it has zero understanding of the task.
Change the environment slightly (e.g., update an interface or move a button), and the poor thing can’t adapt on the fly.
AI agents today lack a genuine concept of overarching goals or the common-sense context that humans use.
They’re essentially text prediction engines.”
I’ve shared my own abysmal experiences with „customer service” AI bots:
Digital Service Dumpster Fires and Shadow Work
Here’s my exploration of the kinds of experiential real-world skills AI won’t master with total capital and operational costs that are lower than the cost of human labor: oops, that hallucination just sawed through a 220V electrical line that wasn’t visible but the human knew was there:
What AI Can’t Do Faster, Better, or Cheaper Than Humans (June 2, 2025)
And here is a selection of my essays on AI, which I have been following since the early 1980s:
Essays on AI
Wait, what did you just say? The AI agent heard something else:

* * *
Check out my new book Ultra-Processed Life and my new novels page.
Become a $3/month patron of my work via patreon.com.
Subscribe to my Substack for free
Tyler Durden
Tue, 07/22/2025 – 11:40

















